
I am a prospective Ph.D. applicant and currently a research intern at ByteDance Seed, where I work on vision-language-action (VLA) models for embodied AI. This work is part of a broader question that motivates me: how can multimodal agents develop spatial intelligence — not only to recognize and describe the world, but to understand space, anticipate change, and act with grounded common sense? SpatialTree (CVPR 2026 Highlight) is my attempt to frame this as a hierarchy from perception to action, and my current VLA work pushes that hierarchy toward real-world interaction. For my Ph.D., I hope to pursue this question at the intersection of embodied AI, multimodal learning, and world models. Please feel free to reach out if my work resonates with yours. Email / CV / Google Scholar / Github |
|
|
I study spatial intelligence as a bridge from multimodal perception to embodied action. My recent work spans evaluating and post-training MLLMs for spatial abilities, building geometry-aware world models, and developing VLA systems that connect vision-language reasoning with real-world interaction. (* indicates equal contribution) |
|
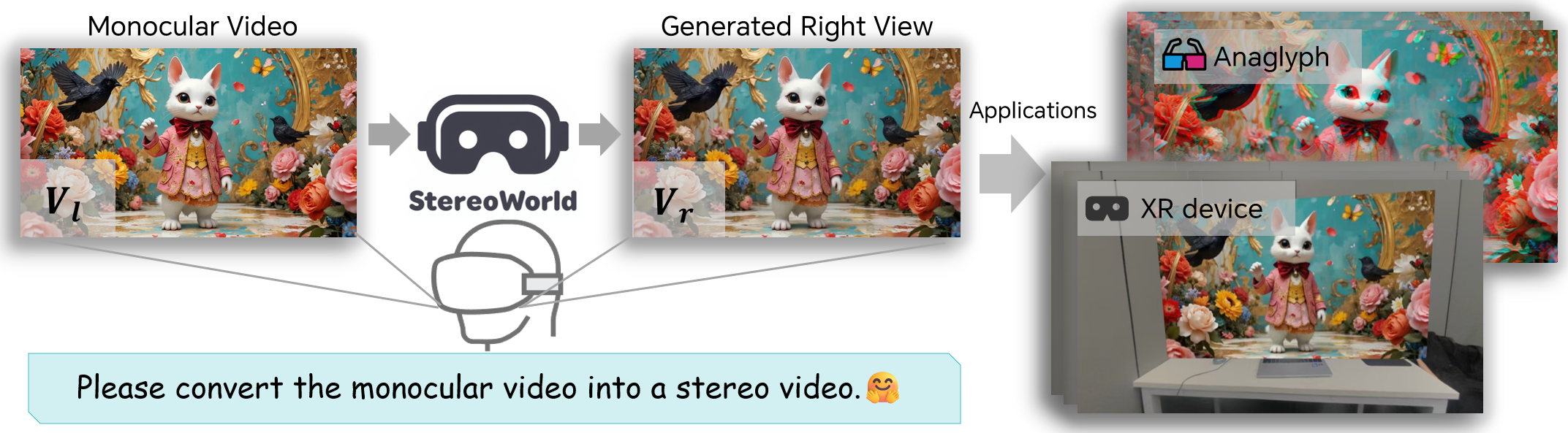
Yuxi Xiao*, Longfei Li*, Shen Yan, Xinhang Liu, Sida Peng, Yunchao Wei Xiaowei Zhou, Bingyi Kang† Project / arXiv / Code |
|
|
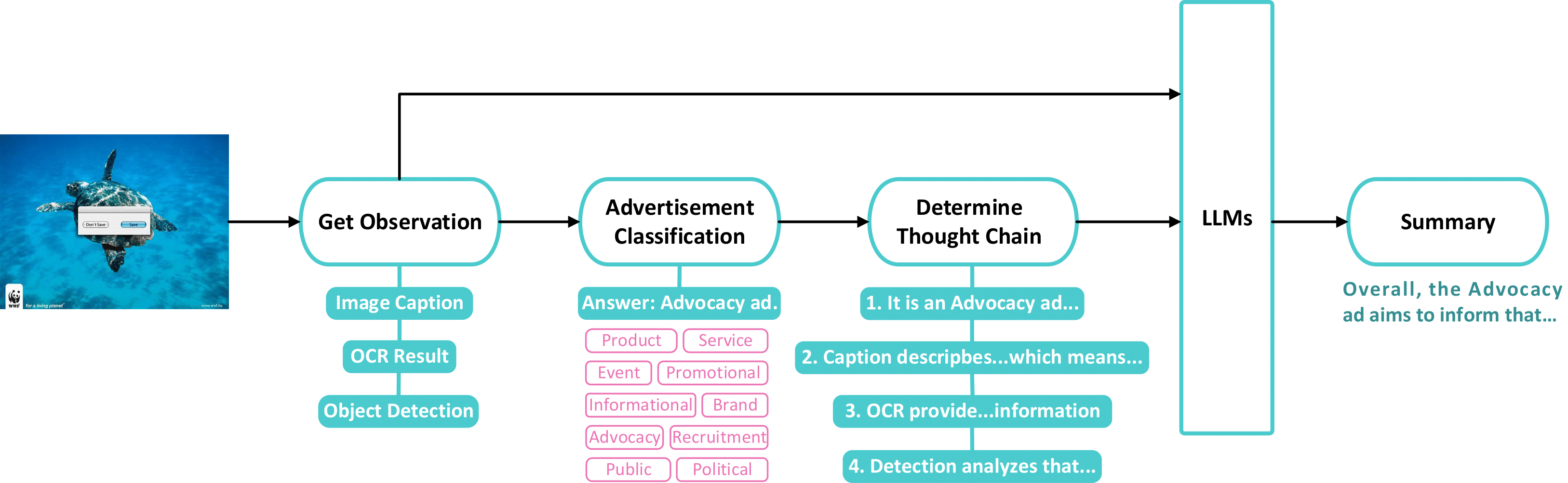
Ke Xing, Longfei Li, Yuyang Yin, Hanwen Liang, Guixun Luo, Chen Fang, Jue Wang, Konstantinos N. Plataniotis, Xiaojie Jin†, Yao Zhao, Yunchao Wei CVPR 2026 Project / arXiv |
|
|
Longfei Li, Zhiwen Fan, Wenyan Cong, Xinhang Liu, Yuyang Yin, Matt Foutter, Panwang Pan, Chenyu You, Yue Wang, Zhangyang Wang, Yao Zhao, Marco Pavone, Yunchao Wei† NeurIPS 2025 Project / arXiv / Code |
|
| Show other publications → | |

|
|
|
Beijing Jiaotong University
Sep. 2021 - Jun. 2025
B.Eng. in Computer Science and Technology, rank 3 / 78
|
|
|

|
ByteDance Seed
Aug. 2025 - Mar. 2026
Research Intern, advised by Dr. Bingyi Kang
Mar. 2026 - Present
Research Intern, Vision-Language-Action (VLA) Team
|

|
University of Texas at Austin
Sep. 2024 - Jul. 2025
Research Intern at VITA Group
Advised by Zhiwen Fan
|